μ��SEO�Ż�����վ�ؼ��������ƹ㵽�ٶȿ��յ�1ҳ
152-1580-3335
��վ�ƹ㡢��վ����ר�ң�
רҵ����ʵ����Ч
��վ�ƹ㡢��վ����ר�ң�
רҵ����ʵ����Ч
�ѹ��������ռ�������������
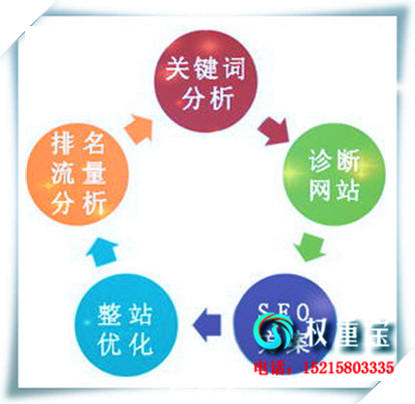
���ļ�����һЩ���ռ�����������õġ����������������û�жࡣ�����ߣ�ʵ�ڽ���Ҫ���ռ����ϣ���Ȼ����ץ������ȥ����ô���Ĵ����������
1���ռ������¶ȿ������ԡ�
2���ռ������ܹ�����ץ������ҳ�������
3���ռ������м��ӵĴ洢����
4���ռ�����������ܵİ�����ҳ���²�������
5���ռ�����ķ�����Ƶ���
��ô�������ԣ�ʵ��Ҳ����Ҫ���ˣ��������������أ�Ҫ������Щ�����أ�
1��url �ı���ս����
���� larbin ����ʮ�ֵĺã�ʵ�ڹ���url�ı����Ǻܼ��ӵģ��ȷ���
cat [what you got]�� tr \" \\n �� gawk '{print $2}' �� pcregrep ^
���ܹ����һ�����ɵ� url �б�
2�������� VS ���߳�
���г����ˣ����һ̨һ���PC �ȷ� booso һ���ܹ�����ſ��5��G�����ݡ�ԼĪ20����ҳ��
3�������������
���������dz�żȻ�����Ȩ�أ�һͨ������תͷ��һͨ������
����������һ�����ĵ�����Ҫ����һ��ֹͣ�������������5�νԳ��б���ô�����Ǹ���ҳ�Ĺ����������ҹ1����
����һ����ҳ���ڳ���5�������ʱ�ֽ��и��£���ô�����õ����빤������Ϊ������1��2��
���⣬��������ʤ����Ŧ֮һ��
4����������Ǽ��أ�
��״���ˡ�����������ţ���м���̨Ч�������ռ����棬��Ȱ��������һ�档
������ͬ��һ��ֻҪһ̨Ч�������ռ����棬��ô����һ��ͳ�����õ����ã�
��ҳ��ȣ���ҳ��������ҳ��Ҫˮƽ
0 : 1 : : 10
1 :20 : :8
2: :600: :5
3: :2000: :2
4 above: 6000: ��ͨû���ƽ�
���ˣ������������û�ж��ˣ����һ������������ҹ��3��4����������Ҫ��ȷ�����˺ܶ࣬�ǽ���“���µ������֣����ֵ������顣
5��������ͨû��֮������Բ����ҳ����ͨ�Ǿ��ɹ���һ��Proxy�������Ǹ�proxy�м���ѹ���Ĺ��ã���Ϊ����Բ����ҳ���и��µ�ʱ�֣�ֻҪ�õ� header �� tag���ܹ��ˣ�������Ҫ�ֲ�����һ���ˣ��ܹ���ҹ��ҹ��ʡ�ռ�������
apache webserver������ص� 304 ��ͨ���DZ�cache���ˡ�
6�����пյ�ʱ���տ�һ��robots.txt
7���洢���졣
��С��˽���˶��ǣ��ȸ� �� gfs ��ϵ����������7��8̨Ч��������Ȱ����NFS��ϵ���������70��80��Ч�����Ļ��ҳ�������afs ��ϵ�������ֻҪһ̨Ч��������ô���⡣
��һ������Ƭ�Σ�����д����Ϣ����ϵͳ������ֹͣ���ݴ洢�ģ�
NAME=`echo $URL ��perl -p -e 's/([^\w\-\.\@])/$1 eq "\n" ? "\n":sprintf("%%%2.2x",ord($1))/eg'`mkdir -p $AUTHOR
newscrawl.pl$URL--user-agent="news.booso+(+booso)"-outfile=$AUTHOR/$NAME
�������������¼��䣺
1.����������һ�����ĵ�����Ҫ����һ��ֹͣ�������������5�νԳ��б���ô�����Ǹ���ҳ�Ĺ����������ҹ1��������һ����ҳ���ڳ���5�������ʱ�ֽ��и��£���ô�����õ����빤������Ϊ������1��2��
��ҳ����Ƶ���Ͼ�Ӱ��������ϵͳ֩��ˮƽ����վ�����룬�������Խ����ζ����ҳ֧¼���ʻ�Խ��ҹ��֧¼��ĿԽ�֧࣬¼��SEO�����һ�����ڡ�
2.���ˣ������������û�ж��ˣ����һ������������ҹ��3��4����������Ҫ��ȷ�����˺ܶ࣬�ǽ���“���µ������֣����ֵ������顣
ֻ�ܽ���վ������������Ŀ���ڣ�����������ҳ�������ϵͳ��ȥ����ҹ��ѹ������Ȼ������Google�г����Ч����ȥ������Щѹ�������Ӳ���ȥ����3��Ŀ���µ���ҳ��ץ�뼰���µ�Ƶ��Ҫ�����ࡣǰ��ҵ�����Ҫ���ʹ��վ��������ս��������ϣ��DZ�����URL���������룬������ܹ��鳭��ǰ̨���ɵľ�̬��ҳ��ʵ��Ŀ���м��㣬˼���ܷ��ܹ��Ż�
ע�������վ��������������Ʋ�����վ�̳�Ƶ����

�����Ϣ
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|